CVR预估模型ESMM
1 序言
广告的链路通常是曝光(impression)->点击(click)->转化(conversion),所以通常会需要开发两种模型CTR模型和CVR模型,CTR模型是取所有的曝光数据为样本空间进行模型建模,CVR模型是取从所有点击数据为样本空间做模型建模。CVR模型相比CTR模型有两个问题:
Sample Selection Bias (SSB),即样本选择偏差,CVR模型建模的空间是点击到转化的样本空间,而预测时却是对整个大空间进行预估,并不是单单从点击开始(因为无法预知是否点击),如下图所示,训练所用的数据与实际预测的数据可能来自不同分布,所有存在很大的偏差。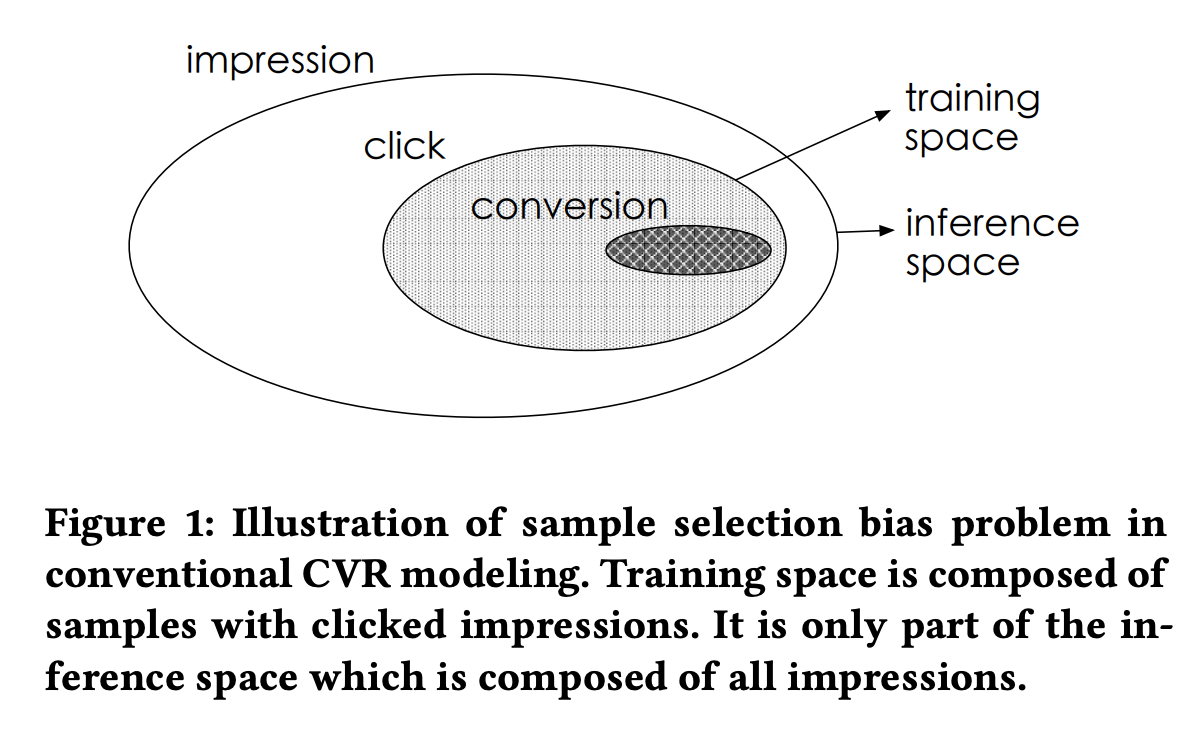
Data Sparsity (DS),即数据的稀疏性,CVR模型建模的数据量仅仅可能只占实际预测数据的百分之几,而且CVR模型中的正样本数据数量也很小,存在正样本数据稀疏。
2 ESMM网络结构
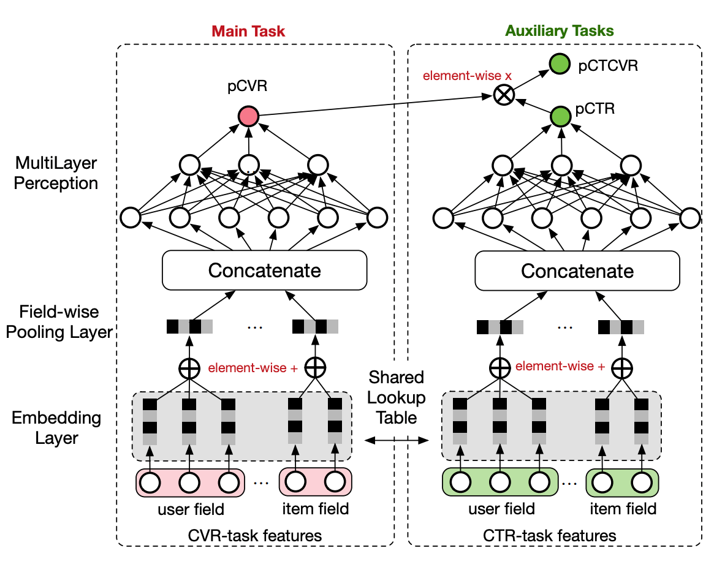
ESMM模型结构如上图所示,属于MTL的模型结构,CVR模型作为主任务模型,CTR模型作为辅助任务模型,底部的Embedding层进行参数共享,每个任务又独享自己的网络结构和网络参数; 在辅助任务CTR模型($y$表示click)中
\[pCTR=\frac{click}{impression}=p(y=1 | x)\]主任务CVR模型($z$表示conversion)中输出为
\[pCVR=\frac{conversion}{click}=p(z=1 | y=1, x)\]而ESMM的建模样本中的两个label分别是click label属于曝光(impression)->点击(click)和conversion label属于曝光(impression)->转化(conversion),这里不包含CVR模型的label,ESMM采用概率迁移的思路,引入曝光转化任务CTCVR模型,表示为
\[pCTCVR=\frac{conversion}{impression}=\frac{click}{impression}\times\frac{conversion}{click}\]即 \(pCTCVR=pCTR*pCVR \\\)
用$y$表示click label,$z$表示conversion label,那么
\[p(z=1,y=1 | x) = p(y=1 | x) * p(z=1 | y=1, x)\]最终loss的计算为
\[L(\theta_{cvr}, \theta_{ctr})=\sum_{i=1}^{N} l(y_i, f(x_i, \theta_{ctr})) + \sum_{i=1}^{N} l(y_i \& z_i, f(x_i, \theta_{ctr})*f(x_i, \theta_{cvr}))\]这样利用CTCVR和CTR的监督信息来训练网络,隐式地学习CVR模型;
ESMM模型的优化后续可以通过调整CTR和CVR两个任务的模型结构,原论文中只是使用了相同的DNN结构,这个网络结构可以被替换成任意的模型,还有可以调整loss的计算权重,引入$\lambda$参数,这样做的原因是ctr模型的loss一般远远大于ctcvr模型的loss,所以可以增大loss权重引导模型训练
\[loss = loss_{ctr} + \lambda * loss_{ctcvr}\]