多任务模型MMoE
0 序言
多任务学习就是通过共享表示信息,同时学习多个相关任务,使得这些任务取得比单独训练一个任务更好的效果,使得模型具有更好的效果。简单来说,就是把多个任务一起训练,共享一些参数,使得模型既能学习好自己的任务,同时又能借助其他任务,学到一些其他信息,使得模型效果更好,所以任务之间相关性越好,模型从其他任务中学到的其他有用的信息就越多,对于模型的提升就越明显。
1 MMoE模型
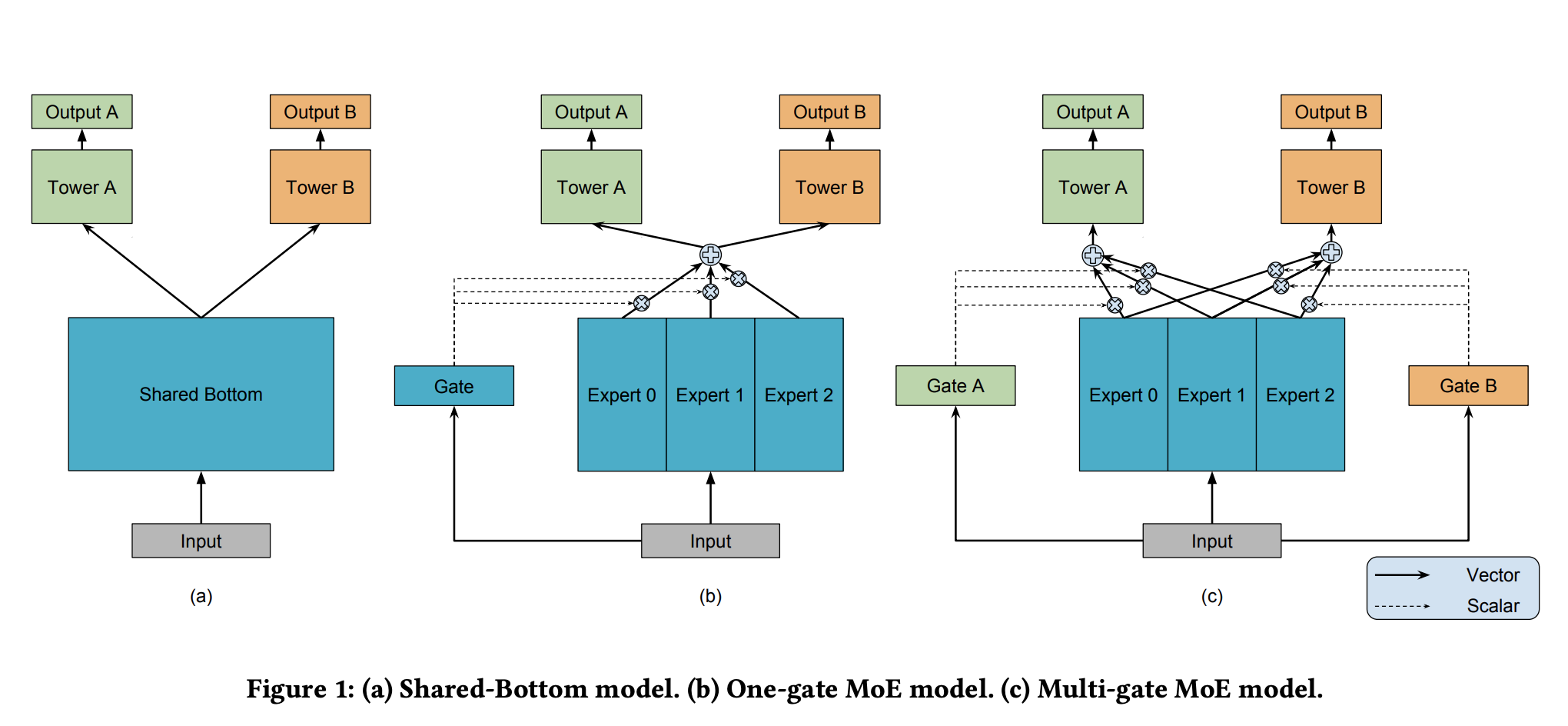
1.1 Shared-Bottom Model
常见的多任务模型如图a所示,这个模型结构称之为Shared-Bottom Model,主要是共享底部参数,然后每个子任务分别对应一个Tower Network,最后各个任务输出自己的Output。用$f(x)$表示Shared Bottom,$h^{k}(x)$表示Tower Network,那么整个网络的输出表示为
\(y_k = h^{k}(f(x))\)
Shared-Bottom Model的优点是浅层参数共享,互相补充学习,缺点是如果任务相关性很低,那么效果会负向。
1.2 OMoE Model
One-gate MoE model的提出是为了解决Shared-Bottom Model不相关任务联合学习效果不佳的问题,结构如图b所示,它用一组Expert Network替换Shared Bottom结构,并且使用一个Gate Network控制一组Expert Network中每个Expert的概率,这样达到共享的目的,Gate Network的概率输出是任务相关性值。用$y_k$表示第$k$个任务的输出,$g(x)$表示Gate Network,$f_{i}(x)$表示第$i$个Expert Network的输出,那么
门控网络Gate Network表示为
\(g(x) = Softmax(W_g x)\)
MoE结构的输出表示为
\(f^k(x) = \sum_{i=1}^{n} g(x)_{i} f_i(x)\)
整个网络的输出表示为
\(y_k = h^{k}(f^k(x))\)
1.3 MMoE Model
Multi-gate MoE是在OMoE的结构上新增了多个Gate Network,对于每个任务都有自己独有的门控网络,结构如图c所示,MoE都是所有任务共享同一个门控网络,现在优化成每个任务拥有自己的门控网络,这样改进可以针对不同任务得到不同的Experts权重,从而实现对Experts的选择性利用,不同任务对应的门控网络可以学习到不同的Experts组合模式,因此模型更容易捕捉到子任务间的相关性和差异性,所以门控网络Gate Network输出表示为
\(g^k(x) = Softmax(W_{gk} x)\)
MMoE结构的输出表示为
\(f^k(x) = \sum_{i=1}^{n} g^{k}(x)_{i} f_i(x)\)
2 MMoE代码实现
官方代码实现地址:keras-mmoe
个人代码实现
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow.keras.layers import Dense, Layer, BatchNormalization, Dropout
class FCN(Layer):
def __init__(self,
hidden_units,
activations,
dropout_rate=0,
use_bn=False,
**kwargs):
self.hidden_units = hidden_units
self.activations = activations
self.dropout_rate = dropout_rate
self.use_bn = use_bn
super(FCN, self).__init__(**kwargs)
def build(self, input_shape):
super(FCN, self).build(input_shape)
def call(self, inputs, training=None, **kwargs):
x = inputs
for hidden_unit, activation in zip(self.hidden_units, self.activations):
x = Dense(units=hidden_unit, activation=activation, use_bias=True)(x)
x = Dropout(rate=self.dropout_rate)(x)
if self.use_bn:
x = BatchNormalization()(x)
return x
def compute_output_shape(self, input_shape):
if len(self.hidden_units) > 0:
shape = input_shape[:-1] + (self.hidden_units[-1],)
else:
shape = input_shape
return tuple(shape)
def get_config(self):
config = {
'hidden_units': self.hidden_units,
'activations': self.activations,
'dropout_rate': self.dropout_rate,
'use_bn': self.use_bn,
}
base_config = super(FCN, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
class MMoE(Layer):
def __init__(self, task_num,
num_expert=8,
expert_hidden_units=None,
expert_activations=None,
gate_hidden_units=None,
gate_activations=None
):
# default value
if gate_activations is None:
gate_activations = ['relu', 'relu', 'relu']
if gate_hidden_units is None:
gate_hidden_units = [128, 64, 32]
if expert_activations is None:
expert_activations = ['relu', 'relu', 'relu']
if expert_hidden_units is None:
expert_hidden_units = [128, 64, 32]
# tower param
self.task_num = task_num
# expert param
self.num_expert = num_expert
self.expert_hidden_units = expert_hidden_units
self.expert_activations = expert_activations
# gate param
self.gate_hidden_units = gate_hidden_units
self.gate_activations = gate_activations
super(MMoE, self).__init__()
def build(self, input_shape):
super(MMoE, self).build(input_shape)
def call(self, inputs, **kwargs):
expert_outputs = []
for idx in range(self.num_expert):
expert = FCN(hidden_units=self.expert_hidden_units,
activations=self.expert_activations)(inputs)
expert_outputs.append(expert)
expert_output = tf.stack(expert_outputs, axis=1)
outputs = []
for idx in range(self.task_num):
gate = FCN(hidden_units=self.gate_hidden_units,
activations=self.gate_activations)(inputs)
gate_output = Dense(self.num_expert, activation='softmax')(gate)
gate_output = tf.expand_dims(gate_output, 1)
output = tf.matmul(gate_output, expert_output)
outputs.append(output)
return outputs
3 参考资料
[1] 多任务学习之MMOE模型
[2] keras-mmoe
[4] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts